No matter what you use your computer for, there has probably been at least one occasion where you needed to download something, and opening a browser felt like overkill. This would be a great use case for cURL.
As the name suggests, cURL is a command-line tool for transferring data with URLs. One of the simplest uses is to download a file via the command line. This is deceptive, however, as cURL is an incredibly powerful tool depending on how you use it. Even if you’re somewhat familiar with the command, you probably aren’t using it to its full potential.
Basic cURL Functionality
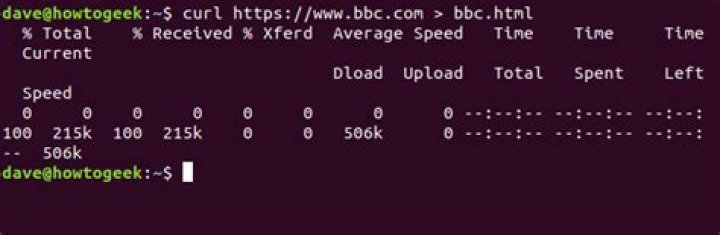
One of the most basic things you can do with cURL is download a webpage or file. To do this you just use the curl command followed by a URL. Here’s an example:
Most of the time, using the command this way will get you a terminal full of raw HTML at best and a wash of unrecognizable characters at worst. If you would rather save it to a file, you can use standard Unix-style redirects to do so.
Follow HTTP Headers
Your browser often fixes this for you, but the Internet is very specific. When you type in a URL, there’s a good chance that you may be redirected one or more times before you reach your destination.
Say for example that you’re trying to reach the Make Tech Easier website. Typing the following will simply get you a redirect notice:
You can follow these HTTP location headers by using the -L flag like so:
This won’t look great in your terminal, but it’s a good option to know.
Save cURL Results to a File
There are a few ways to save a URL’s contents to a file. The -o option lets you decide the filename, while the -O option uses the filename in the URL to save. To choose your own file, use the following option:
More often than not, you’ll want to save a file to the same name it uses on the server. For that, use the -O option.
Download Multiple Files at Once
If you need to download a few files at the same time, cURL makes that easy to do. You’ll typically want to use this with the -O option.
When you download this way, cURL will try to re-use the connection instead of making new connections each time.
Continue a Stopped Download
It’s never fun when a download stops halfway through. Fortunately, cURL makes it easy to resume a download without having to start over. The syntax is somewhat strange, as you need to add -C – to your command.
Say you started a download with the following:
Then you stopped it by pressing Ctrl + C . You can resume it with the following command:
Use Basic HTTP Authentication
This won’t work for everything that requires a username and password, but if a server uses basic HTTP authentication, cURL can work with it. To download a file with username/password authentication, you can use the following:
This also works with FTP servers, as cURL supports a ton of different protocols.
Conclusion
There’s just a whole lot you can do with cURL. Sometimes all this functionality might feel like too much. If cURL feels too feature-rich and arcane to you, there is a simpler alternative: GNU wget.
While cURL gives you all the options you could possibly want, wget aims to provide good default options for you. Not sure if this is what you’re looking for? Don’t worry, we’ve got a detailed comparison of cURL and wget that should help you figure out which is the right one for you.
Kris Wouk is a writer, musician, and whatever it’s called when someone makes videos for the web.
- Tweet
Affiliate Disclosure: Make Tech Easier may earn commission on products purchased through our links, which supports the work we do for our readers.
curl is a command line tool to transfer data to or from a server, using any of the supported protocols (HTTP, FTP, IMAP, POP3, SCP, SFTP, SMTP, TFTP, TELNET, LDAP or FILE). curl is powered by Libcurl. This tool is preferred for automation, since it is designed to work without user interaction. curl can transfer multiple file at once.
Syntax:
URL : The most basic uses of curl is typing the command followed by the URL.
This should display the content of the URL on the terminal. The URL syntax is protocol dependent and multiple URLs can be written as sets like:
URLs with numeric sequence series can be written as:
Progress Meter: curl displays a progress meter during use to indicate the transfer rate, amount of data transferred, time left etc.
If you like a progress bar instead of meter, you can use the -# option as in the example above, or –silent if you want to disable it completely.
Example:
Options:
- -o : saves the downloaded file on the local machine with the name provided in the parameters.
Syntax:
Example:
Output:
The above example downloads the file from FTP server and saves it with the name hello.zip.
-O : This option downloads the file and saves it with the same name as in the URL.
Syntax:
Example:
Output:
-C – : This option resumes download which has been stopped due to some reason. This is useful when downloading large files and was interrupted.
Syntax:
Example:
–limit-rate : This option limits the upper bound of the rate of data transfer and keeps it around the given value in bytes.
Syntax:
Example:
Output:
The command limits the download to 1000K bytes.
-u : curl also provides options to download files from user authenticated FTP servers.
Syntax:
Example:
Example:
-T : This option helps to upload a file to the FTP server.
Syntax:
If you want to append a already existing FTP file you can use the -a or –append option.
–libcurl :This option is very useful from a developers perspective. If this option is appended to any cURL command, it outputs the C source code that uses libcurl for the specified option. It is the code similar to the command line implementation.
Syntax:
Example:
Output:
The above example downloads the HTML and saves it into log.html and the code in code.c file. The next command shows the first 30 lines of the code.
-x, –proxy : curl also lets us use a proxy to access the URL.
Syntax:
If the proxy requires authentication, it can be used with the command:
Sending mail : As curl can transfer data over different protocols, including SMTP, we can use curl to send mails.
Syntax:
curl –url [SMTP URL] –mail-from [sender_mail] –mail-rcpt [receiver_mail] -n –ssl-reqd -u
: -T [Mail text file]
Syntax:
Example:
Output:
Note: There are a number of other options provided by cURL which can be checked on the man page. The Libcurl library has been ported into various programming languages. It’s advisable to visit the individual project site for documentation.
The curl tool or command is used to download different files and directories from the command line. The curl is provided by all major Linux distributions like Ubuntu, Debian, Mint, CentOS, etc.
Install curl
The curl tool or command is not installed by default. In order to use it, it should be installed with the apt install or dnf install command. In order to install Ubuntu, Debian, Mint, Kali use the following command.
The CentOS, Fedora, RHEL use the following command in order to install curl.
curl Version
The installed curl command version can be printed with the –version option. This will also print supported protocols list and some required libraries about the curl command.
The output is like below.
curl Help
The curl is a very advanced tool that provides a lot of different options. Help information about curl and these options can be displayed with the -h or –help option like below.
Download File
By default, the downloaded content will be printed to the standard output which is the current terminal and not stored as a file. The -o options can be used to store as a file where we should also provide the file name. In the following example, we will set the downloaded file name as sample.txt.
We can see that a lot of information about the download is displayed.
- % Total is the total amount of the data to be retrieved.
- % Received is the percentage of data retrieved so far.
- % Xferd is the percentage of data uploaded so far.
- Average Download Speed
- Average Upload Speed
- Time Total
- Time Spent
- Time Left
- Current Speed
Alternatively, the stdout operator can be used to redirect the downloaded content into a file. With the following command, the downloaded file content will be redirected into the file named sample.txt.
Do Not Show Progress Bar
By default, the progress bar about the download is displayed. Even this progress bar provides useful information we may want to disable or hide this progress bar and download will be completed silently. The silent option can be provided with the -s or –silent option like below.
Show Progress Bar As #
By default the progress bar provides information as text but also the progress bar can be displayed as # for downloaded percentage. Also the downloaded percentage will be displayed as number.
Resume Interrupted Download
While downloading big files like movies, media, images, ISO files, etc they may can a lot of time. If the download is interrupted for different reasons like system shutdown, network problem, or remote server problem even we can cancel it. We can continue the download from where we left and already downloaded content or data will be preserved and not downloaded again and it will continue where we left. the -C which is the short form of the –continue can be used to resume interrupted download.
Redirect Downloaded File Content Into Another Command
The curl command is generally used with the -o option where the downloaded file name is provided and the downloaded file content will be put into this file. If not provided the content is printed into the standard output which is the current terminal. We can use this default behavior in order to redirect downloaded content or data into another command by using the bash pipe operators. In the following example, we will redirect the file content into the wc command which will count the characters, words, and sentences in the given data.
The output is like below where the sentence count is 3, word count is 88 and character count is 607.
How to download a file with curl command
The basic syntax:
- Grab files with curl run: curl
- Get files using ftp or sftp protocol: curl ftp://ftp-your-domain-name/file.tar.gz
- You can set the output file name while downloading file with the curl, execute: curl -o file.pdf
- Follow a 301-redirected file while downloading files with curl, run: curl -L -o file.tgz
Let us see some examples and usage about the curl to download and upload files on Linux or Unix-like systems.
Installing curl on Linux or Unix
By default curl is installed on many Linux distros and Unix-like systems. But, we can install it as follows:
## Debian/Ubuntu Linux use the apt command/apt-get command ##
$ sudo apt install curl
## Fedora/CentOS/RHEL users try dnf command/yum command ##
$ sudo dnf install curl
## OpenSUSE Linux users try zypper command ##
$ sudo zypper install curl
Verify installation by displaying curl version
Type:
$ curl –version
We see:
Downloading files with curl
The command syntax is:
curl url –output filename
curl -o output.file.name
Let us try to download a file from and save it as output.pdf
curl -o output.pdf
OR
curl –output output.pdf
The -o or –output option allows you to give the downloaded file a different name. If you do not provide the output file name curl will display it to the screen. Let us say you type:
curl –output file.html
We will see progress meter as follows:
The outputs indicates useful information such as:
- % Total : Total size of the whole expected transfer (if known)
- % Received : Currently downloaded number of bytes
- % Xferd : Currently uploaded number of bytes
- Average Dload : Average transfer speed of the entire download so far, in number of bytes per second
- Speed Upload : Average transfer speed of the entire upload so far, in number of bytes per second
- Time Total : Expected time to complete the operation, in HH:MM:SS notation for hours, minutes and seconds
- Time Spent : Time passed since the start of the transfer, in HH:MM:SS notation for hours, minutes and seconds
- Time Left : Expected time left to completion, in HH:MM:SS notation for hours, minutes and seconds
- Current Speed : Average transfer speed over the last 5 seconds (the first 5 seconds of a transfer is based on less time, of course) in number of bytes per second
Resuming interrupted downloads with curl
Pass the -C – to tell curl to automatically find out where/how to resume the transfer. It then uses the given output/input files to figure that out:
## Restarting an interrupted download is important task too ##
curl -C – –output bigfilename
How to get a single file without giving output name
You can save output file as it is i.e. write output to a local file named like the remote file we get. For example, sticker_book.pdf is a file name for remote URL One can save it sticker_book.pdf directly without specifying the -o or –output option by passing the -O (capital
curl -O
Downloading files with curl in a single shot
The curl command transfers data to or from a network server. It is by default available in all Linux-based systems. It is commonly used to troubleshoot URL accesses and for downloading files. Curl supports a wide variety of protocols including HTTP, HTTPS, FTP, FTPS, SFTP etc. If you haven’t specified any protocols explicitly it will default to HTTP. Curl is powered by libcurl for all transfer-related features.
Curl offers a lot of useful tricks such as proxy support, user authentication, FTP upload, HTTP post, SSL connections, cookies, file transfer resume, Metalink, and more.
In this tutorial, we will discuss how to use curl command and its basic options with examples.
If you don’t find curl installed in your Linux systems, use the following commands:
To install curl on Ubuntu/Debian
To install Curl on CentOS/Fedora
How to use curl command
- options – The curl options starting with one or two dashes.
- URL – URL of the remote server.
Curl command followed by website URL display the source code website to the standard output.
To print the source code of
You can pass the URL as input to the curl command, and redirect the output to a file.
Download a file with same name
To download a file and save with the same name, use -O option.
For example to download Ubuntu 20.04 iso file, type:
Verify the downloaded file:
To download a file and save it with a custom name, use -o option.
To verify, use ls command:
Download multiple files
To download multiple files at once, use multiple -O flags followed by the URL of the files.
To save multiple files using different names, use nested -o option.
Download files which has numeric sequence, type:
Download/Upload via FTP
To access a protected FTP server with the curl command you need to use the -u flag with a username and password.
The following command will list all of the files and directories in the user’s home directory.
To download the file use:
To upload the file to FTP server use the -T flag:
NOTE: If the FTP server allows anonymous logins, you don’t need to use -u username:password
Upload file
Curl emulate a filled-in form where a user has pressed the submit button, using -F option.
For example to POST data using the Content-Type multipart/form-data:
Resume an Interrupted Download
If a download was interrupted for some reason, you can resume it using the option -C – to resume the download beginning where it left off.
Curl to Get HTTP Headers
To fetch the HTTP header only use the -I option. When used on an FTP or FILE file, displays the file size and last modification time only.
Curl to Follow Redirect
Sometimes you may come across an URL that gets errors like “Moved” or “Moved Permanently”. This usually happens when the URL redirects to some other URL.
For example, from the output google.com redirects to an www URL, so you get an error like the following:
To tell curl to follow the redirect, use the -L option.
Use case 1: If the URL from where you are trying to download the files has any 301 redirect, you may not get the file downloaded. For example, if the URL has http to https redirection, you have to use the option -L to follow the redirect and download.
Use case 2: To check a remote server support http2 use -L followed by –http2. For example
If the output shows HTTP/2 200, indicates that remote server supports HTTP/2.
Limit the Maximum Transfer Rate
Usage for limiting the data transfer rate is:
The value can be expressed in bytes, kilobytes with the k suffix, megabytes with the m suffix and gigabytes with the g suffix.
The following command will limit the download speed to 1mb:
Skip SSL certs
By default, curl verify every SSL connection it makes. Sometimes you face issues downloading files due to SSL/TLS error or test API endpoint using a self-signed certificate or an invalid one. In such cases skip the SSL using -k option.
Verify Self Signed Certificate
To verify your self signed cert in curl, use –cacert option.
Specify User-agent string
To specify user-agent string to send to HTTP server use -A option.
Use case: Some http server block curl user-agent to download files, in such situations curl allows to specify user-agent. For example:
Specify Proxy
To use the specified HTTP proxy to download use -x option. If the port number is not specified, it is assumed at port 1080.
For example to download file using specific proxy 192.168.35.8 on port 8080, type:
Use -U or –proxy-user option to specific the authentication username and password.
To Store/Pass Cookies
To write cookies to a file that are downloaded when you access a resource, use –cookie-jar or -c option followed by text file name to store it.
For example to store cookies from to file named cookies.txt, use:
You can tell curl reuse cookies received before by using -b or –cookie option followed by filename containing the cookies or a string. This will pass the data to the HTTP server as a cookie. By default, curl doesn’t use cookies to request resources.
Total time for a request
To get the total time curl took for a request to be successful use -w option.
For example to print total time after transfer complete to download ubuntu 20.04 iso file after transfer complete.
Local Name resolution
To test local version of a resource for example API endpoint use –resolve option. This developers to test an API for deploying.
Progress meter
Curl by default shows a progress meter when uploading or downloading data. It will indicate information such as total size, how much % and size received, time spent, time left, current speed, etc.
To show an alternative progress meter use -# or –progress-bar. For example:
To disable the progress meter, use –silent or -s.
Conclusion
In this tutorial, we learned how to use curl command to transfer data in Linux. If you want to learn more about curl visit the Curl Documentation page. Please let me know your thoughts and suggestions on this tutorial on the below comment section.
Curl started its journey back in the mid-1990s when the Internet was still a new thing. Daniel Stenberg, a Swedish programmer, started the project that eventually became curl. He aimed to develop a bot that would download currency exchange rates from a webpage periodically and provide Swedish Kronor equivalents in USD to IRC users. The project was successful and, thus, curl was born.
Over time, curl was further improved with the addition of new internet protocols and features. In this guide, check out how to use curl to download a file.
Installing curl
Today, you will find curl pre-installed in most of the Linux distros. Curl is quite a popular package and is available for any Linux distro. However, there is no guarantee that curl is currently installed in your distro.
Run the command according to your distro type to install curl on your system.
To install curl on Debian/Ubuntu and derivatives, enter the following:
To install curl on RHEL, CentOS, Fedora, and derivatives, enter the following:
To install curl on OpenSUSE and derivatives, enter the following:
To install curl on Arch Linux and derivatives, enter the following:
Curl is open-source software. You can grab the curl source code and compile it manually. However, this process is more complex and should be avoided if you intend to use curl for more than testing or redistributing/packaging.
The following process was demonstrated in Ubuntu. For an in-depth guide on compiling curl, check out the official curl documentation.
Download the curl source code here. I have grabbed the latest version of the curl source code. At the time of writing this article, the latest version is curl v7.72.0.
Extract the archive.
Run the configuration script.
Start the compilation process.
Finally, install the curl program that we just compiled.
Using curl
To demonstrate the usage of the curl program, first, we need a dummy file to download. Any online file will work for this, as long as you have the direct download link. For this guide, I will use the small file provided by think broadband.
Curl Version
Check out the version of curl by entering the following:
Download File Using curl
This is a very basic way of using curl. We will download the dummy file. Here, the “-O” flag tells curl to download and save the file in the current directory.
To download and save the file with a different file name, use the “-o” flag. With this flag, the file will be downloaded and saved at the current working directory.
Download Multiple Files
Need to download multiple files? Follow the command structure shown below. Use either “-o” or “-O” as necessary.
Progress Bar
By default, curl does not show any progress bar. To enable the progress bar, use the “-#” flag.
Silent Mode
If you want curl to print no output, use the “–silent” flag.
Speed Limit
Curl allows you to limit the download speed. Use the “–limit-rate” flag, followed by the bandwidth limit, to do so. Here, the download speed is limited to 1mb.
Manage FTP Server
It is also possible to manage an FTP server using curl. Assuming that the FTP server is protected, you will need to use the “-u” flag, followed by the username and password. If no file is specified, curl will print a list of all the files and directories under the user’s home directory.
Downloading files from an FTP server is like the method shown before. However, assuming the FTP server requires user authentication, use the following command structure:
To upload a file to the FTP server, use the following command structure:
User Agent
In certain situations, the URL that you are trying to access may be blocked due to a lack of a proper user agent. Curl allows you to define the user agent manually. To do so, use the flag “-A,” followed by the user agent. As for the user agent, you can use the User Agents randomizer. If you want a custom user agent, then you can find one from WhatIsMyBrowser.
Final Thoughts
Despite it being a simple and lightweight tool, curl offers tons of features. Compared to other command-line download managers, like wget, curl offers a more sophisticated way of handling file downloads.
For in-depth information, I always recommend checking out the man page of curl, which you can open with the following command:
Last Validated on June 11, 2021 Originally Published on October 5, 2019
Client URL, or cURL, is a library and command-line utility for transferring data between systems. It supports many protocols and tends to be installed by default on many Unix-like operating systems. Because of its general availability, it is a great choice for when you need to download a file to your local system, especially in a server environment.
In this tutorial, you’ll use the curl command to download a text file from a web server. You’ll view its contents, save it locally, and tell curl to follow redirects if files have moved.
Downloading files off of the Internet can be dangerous, so be sure you are downloading from reputable sources. In this tutorial you’ll download files from DigitalOcean, and you won’t be executing any files you download.
Step 1 — Fetching remote files
Out of the box, without any command-line arguments, the curl command will fetch a file and display its contents to the standard output.
Let’s give it a try by downloading the robots.txt file from Digitalocean.com:
You’ll see the file’s contents displayed on the screen:
Give curl a URL and it will fetch the resource and display its contents.
Saving Remote Files
Fetching a file and display its contents is all well and good, but what if you want to actually save the file to your system?
To save the remote file to your local system, with the same filename as the server you’re downloading from, add the –remote-name argument, or use the -O option:
Your file will download:
Instead of displaying the contents of the file, curl displays a text-based progress meter and saves the file to the same name as the remote file’s name. You can check on things with the cat command:
The file contains the same contents you saw previously:
Now let’s look at specifying a filename for the downloaded file.
Step 2 — Saving Remote Files with a Specific File Name
You may already have a local file with the same name as the file on the remote server.
To avoid overwriting your local file of the same name, use the -o or –output argument, followed by the name of the local file you’d like to save the contents to.
Execute the following command to download the remote robots.txt file to the locally named do-bots.txt file:
Once again you’ll see the progress bar:
Now use the cat command to display the contents of do-bots.txt to verify it’s the file you downloaded:
The contents are the same:
By default, curl doesn’t follow redirects, so when files move, you might not get what you expect. Let’s look at how to fix that.
Step 3 — Following Redirects
Thus far all of the examples have included fully qualified URLs that include the https:// protocol. If you happened to try to fetch the robots.txt file and only specified , you would not see any output, because DigitalOcean redirects requests from http:// to https:// :
You can verify this by using the -I flag, which displays the request headers rather than the contents of the file:
The output shows that the URL was redirected. The first line of the output tells you that it was moved, and the Location line tells you where:
You could use curl to make another request manually, or you can use the –location or -L argument which tells curl to redo the request to the new location whenever it encounters a redirect. Give it a try:
This time you see the output, as curl followed the redirect:
You can combine the -L argument with some of the aforementioned arguments to download the file to your local system:
Warning: Many resources online will ask you to use curl to download scripts and execute them. Before you run any scripts you have downloaded, it’s good practice to check their contents before making them executable and running them. Use the less command to review the code to ensure it’s something you want to run.
Conclusion
curl lets you quickly download files from a remote system. curl supports many different protocols and can also make more complex web requests, including interacting with remote APIs to send and receive data.
You can learn more by viewing the manual page for curl by running man curl .
Curl started its journey back in the mid-1990s when the Internet was still a new thing. Daniel Stenberg, a Swedish programmer, started the project that eventually became curl. He aimed to develop a bot that would download currency exchange rates from a webpage periodically and provide Swedish Kronor equivalents in USD to IRC users. The project was successful and, thus, curl was born.
Over time, curl was further improved with the addition of new internet protocols and features. In this guide, check out how to use curl to download a file.
Installing curl
Today, you will find curl pre-installed in most of the Linux distros. Curl is quite a popular package and is available for any Linux distro. However, there is no guarantee that curl is currently installed in your distro.
Run the command according to your distro type to install curl on your system.
To install curl on Debian/Ubuntu and derivatives, enter the following:
To install curl on RHEL, CentOS, Fedora, and derivatives, enter the following:
To install curl on OpenSUSE and derivatives, enter the following:
To install curl on Arch Linux and derivatives, enter the following:
Curl is open-source software. You can grab the curl source code and compile it manually. However, this process is more complex and should be avoided if you intend to use curl for more than testing or redistributing/packaging.
The following process was demonstrated in Ubuntu. For an in-depth guide on compiling curl, check out the official curl documentation.
Download the curl source code here. I have grabbed the latest version of the curl source code. At the time of writing this article, the latest version is curl v7.72.0.
Extract the archive.
Run the configuration script.
Start the compilation process.
Finally, install the curl program that we just compiled.
Using curl
To demonstrate the usage of the curl program, first, we need a dummy file to download. Any online file will work for this, as long as you have the direct download link. For this guide, I will use the small file provided by think broadband.
Curl Version
Check out the version of curl by entering the following:
Download File Using curl
This is a very basic way of using curl. We will download the dummy file. Here, the “-O” flag tells curl to download and save the file in the current directory.
To download and save the file with a different file name, use the “-o” flag. With this flag, the file will be downloaded and saved at the current working directory.
Download Multiple Files
Need to download multiple files? Follow the command structure shown below. Use either “-o” or “-O” as necessary.
Progress Bar
By default, curl does not show any progress bar. To enable the progress bar, use the “-#” flag.
Silent Mode
If you want curl to print no output, use the “–silent” flag.
Speed Limit
Curl allows you to limit the download speed. Use the “–limit-rate” flag, followed by the bandwidth limit, to do so. Here, the download speed is limited to 1mb.
Manage FTP Server
It is also possible to manage an FTP server using curl. Assuming that the FTP server is protected, you will need to use the “-u” flag, followed by the username and password. If no file is specified, curl will print a list of all the files and directories under the user’s home directory.
Downloading files from an FTP server is like the method shown before. However, assuming the FTP server requires user authentication, use the following command structure:
To upload a file to the FTP server, use the following command structure:
User Agent
In certain situations, the URL that you are trying to access may be blocked due to a lack of a proper user agent. Curl allows you to define the user agent manually. To do so, use the flag “-A,” followed by the user agent. As for the user agent, you can use the User Agents randomizer. If you want a custom user agent, then you can find one from WhatIsMyBrowser.
Final Thoughts
Despite it being a simple and lightweight tool, curl offers tons of features. Compared to other command-line download managers, like wget, curl offers a more sophisticated way of handling file downloads.
For in-depth information, I always recommend checking out the man page of curl, which you can open with the following command:
I have been trying to use Curl and wget to download file from Sharepoint. I am planning to make it as Script which runs automatically everyday and download the file from URL.
I tried using CURL with following command
But it gave me error about SSL connection. I got to know that there is some existing bug in CURL 7.35 So i downgraded it to 7.22. But still gives me same error.
I also tried using Wget
But it still gives me error — Unable to establish SSL connection
Can someone please let me know how i can accomplish my task
UPDATE
I was able to resolve the error in CURL. Below is the command that i gave
Now what it downloads is a file, which when i open it shows me Login page of Sharepoint. It does not download the actual excel file.
? – jww Jul 24 ’14 at 12:39
7 Answers 7
Please use rclone
Download and install the latest one from
First option: Use OneDrive to access SharePoint sites/personal folder. This option will help you to upload large files.
1.create rclone configurations using the rclone config command
2.Select New remote and give a name
3.Select cloud storage OneDrive
4.Leave client ID and secret as blank
5.Edit advanced config: n
6.Remote config: Use auto-config: y
7.Open the URL on the browser and give access to rclone
8.Select personal/shared site URL option
8a.Shared site URL option you have to give the site URL. ie;
9.Select personal/Documents drive. Documents drive will show if you selected the shared site URL option in the 8th step
- Save config and quit
And the configuration file contents will be like the following. If you selected the Personal option drive type will be personal.
Second option: In this option, you can upload up to 2 GB-sized files.
1.create rclone configurations using rclone config command
2.Select New remote and give a name
3.Select cloud storage WebDAV
4.Give site URL, username and password
And the configuration file contents will be like the following. Password will be in an encrypted format.
Download a file from SharePoint.
rclone copy –ignore-times –ignore-size –verbose sharepoint:SourceFolder/file.txt DestFolder
Struggled with the same issue myself, and had my not-so-automatic-but-man-so-convenient way, with a daily log-in.
- logged into Sharepoint with a browser,
- exported the cookie,
run the following command.
And files were downloaded just fine.
Firefox plugin that captures the link with session ID etc.. and it provides a command you could paste in the console for curl or wget.
If anyone has a better suggestion please let me know.
It gives you a curl or wget command with headers, cookies and all, with a copy to clipboard button, right on the download dialogue.
Similar to the answer Zyglute gave, using cURL:
Then use the following code:
At some point your Sharepoint session will expire (not sure how long that takes), and you will need a new cookie file.
EDIT: If a malicious user gets a hold of your cookie.txt, they could get into your SharePoint account, so be sure to keep it safe.
Another potential solution to this involves taking your sharepoint link and replacing the text after the ‘?’ with download=1:
Now, you can just:
*Note, this example used a single file and a link where anyone with the link could access the file (no credentials required)
Use wget adding &download=1 at the end of the link.
it will be download with [yourlink] string as name, then just mv with the correct name after.
For anyone using CURL to download a file on Sharepoint with an “Anyone with the link” download option. Below are the steps I had to follow to download. Essentially you have to use the cookie from the share link, and then download the file from a different download link they don’t provide easily for you.
When sending the CURL command for the “share link” it returns a 302 message, a forward link, and a cookie. If we save that cookie and use it to hit a “download” link I am able to download the file. Essentially, Microsoft uses the initial “share link” to send the cookie to the browser, and then redirect to their “View File” website. On that website you need to use the cookie provided (authentication), and select your next function (On screen view, print, download, etc). When you click the download button you hit a different link. I was able to find this link by going to the “view page” website for the file/link, turning on developer tools, and watching the link the browser follows when hitting download. You can then replicate that link for each file. If we use that download link along with the cookie, we can download the file.
